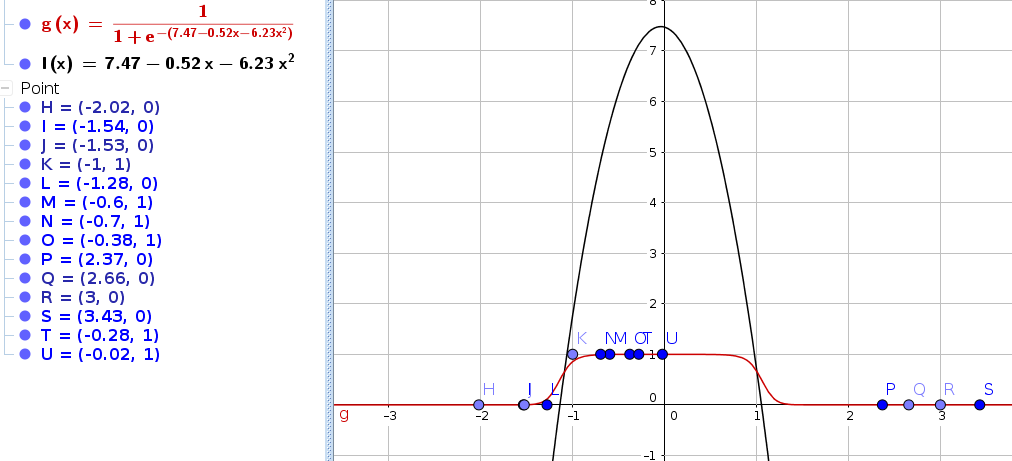
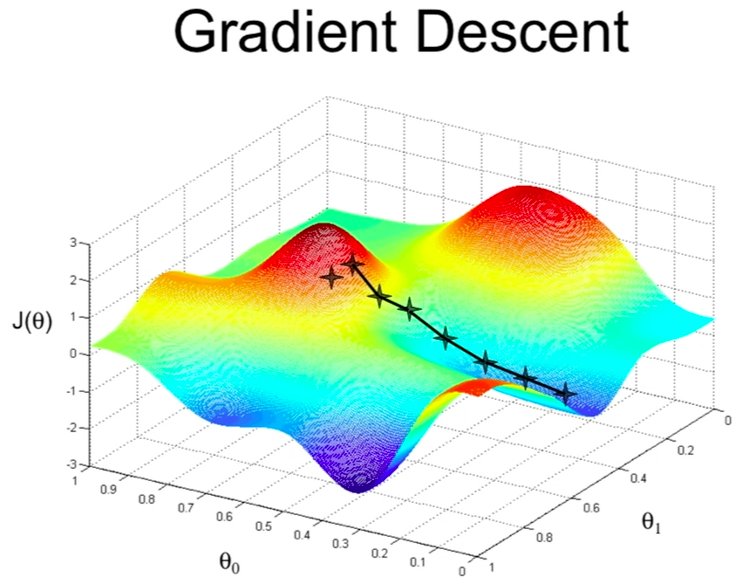
In the last couple of blog posts we used Gradient Descent / Gradient Ascent as our optimization algorithm. Gradient Descent works by computing the derivative and then moving in this direction by a small learning rate.
There are many optimization algorithms out there. In this post we will learn another one called Newtons Method.

The idea behind Newtons Method is finding the root of a function f(x). It works by defining a random x-value like x_1. By putting a tangent in the upper function at the position of x_1 you can calculate the root of the tangent which is your x_2. This is called one iteration. After very few iterations the root of f(x) will be determined very accurately.
Lets put the above paragraph in a mathematical notation. Let’s define the distance of x_1 and x_2 to be \Delta.
x_2 = x_1 - \DeltaThe slope of the function of at a specific point can be expressed as f'(x_1) = \frac{f(x_1)}{\Delta}. So \Delta can be expressed as \Delta = \frac{f(x_1)}{f'(x_1)}.
x_2 = x_1 - \frac{f(x_1)}{f'(x_1)}Let’s say the function f is not dependent on x but on \theta (notice, that \theta here is a scalar not a vector). We want to find the \theta so that f(\theta)=0. Then we can change our iterations to use \theta.
\theta^{(2)} =\theta^{(1)} - \frac{f(\theta^{(1)})}{f'(\theta^{(1)})}In more general terms:
\theta^{(t+1)} =\theta^{(t)} - \frac{ f(\theta^{(t)}) }{ f'(\theta^{(t)}) }.
Now we can use this algorithm to maximize our log-Likelihood function l(\theta) from the previous blog posts. We now from calculus that the maximum of a function has l'(\theta)=0. So we need to fit \theta to find l'(\theta)=0.
\theta^{(t+1)} =\theta^{(t)} -\frac{l'(\theta^{(t)})}{l''(\theta^{(t)})}This is now our new optimization algorithm. It turns out that it works very well for logistic regression. As already mentioned the algorithm is known for the speed of convergence (finding the minimum/maximum). In more technical terms Newtons Method has quadratic convergence. That means that for every iteration the error value (the noise) minimizes quadratic.
Example:
- (1st iteration) -> 0.01 error
- (2nd iteration) -> 0.001 error
- (3rd iteration) -> 0.000 000 1 error
- and so on …
The generalization for Newtons method – when \theta is a vector of our parameters instead of a scalar – looks like the following:
\theta^{(t+1)} =\theta^{(t)} -H^{-1} \bigtriangledown_\theta l(\theta)Where H is the Hessian matrix (matrix of 2nd derivatives of l(\theta).
H_{ij}=\frac{\partial^2 l }{\partial \theta_i\partial \theta_j}For every iteration the Hessian matrix needs to be inverted. This could be computationally expensive for a large number of features.